
Big data processing에서 가장 중요한 양대 operation이 있다면 바로 group by와 join일 것이다. 그 중 join은 특히 실무를 하면서 가장 많이 나를 곤란하게 하는 애증의 상대라고 할 수 있다. 그것은 join이 가장 성능적으로 가장 걸림돌이 많이 되고, 또한 optimize하는 것도 쉽지 않기 때문이다.
Join에 여러 테크닉이 있겠지만, 그 중에서도 가장 깔끔하고 성능도 압도적으로 훌륭한 Broadcast Join에 대해서 간단히 설명하고자 한다.
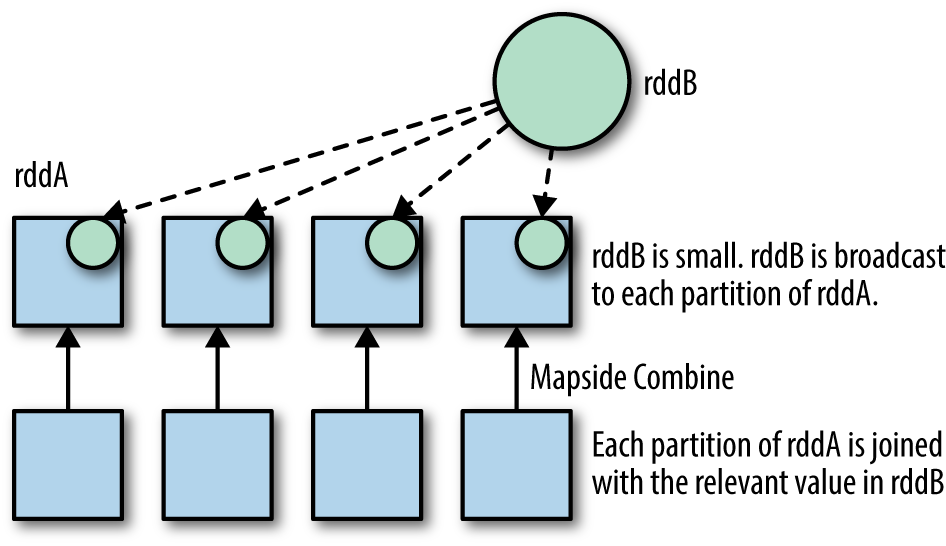
Broadcast Join이 가능한 경우는 join하려는 두 data중 하나의 크기가 executor의 메모리에 들어갈 만큼 작은 경우이다. 즉, 그렇게 작은 data를 아예 executor memory에 hash map형태로 저장한 다음에 다른 data쪽은 shuffle할 필요 없이 local scan으로 작업을 끝내는 형태이다.
빅데이터 처리에서 가장 시간이 많이 들게 만드는 요소가 data shuffling이기 때문에 셔플을 하지 않을 수 있다면 무조건 혜자다 🙂
따라서 데이터를 잘 분석해서 Broadcast Join을 사용할 수 있다면 반드시 사용해야 함을 잊지 말자!
